



The ever growing need to efficiently store, retrieve and analyze massive datasets, originated by very different sources, is currently made more complex by the different requirements posed by users and applications. Such a new level of complexity cannot be handled properly by current data structures for big data problems.
To successfully meet these challenges, we launched a project, funded by the Italian Ministry of University and Research (PRIN no. 2017WR7SHH), that will lay down the theoretical and algorithmic-engineering foundations of a new generation of Multicriteria Data Structures and Algorithms. The multicriteria feature refers to the fact that we wish to seamlessly integrate, via a principled optimization approach, modern compressed data structures with new, revolutionary, data structures learned from the input data by using proper machine-learning tools. The goal of the optimization is to select, among a family of properly designed data structures, the one that “best fits” the multiple constraints imposed by its context of use, thus eventually dominating the multitude of trade-offs currently offered by known solutions, especially in the realm of Big Data applications.
A multicriteria data structure, for a given problem $P$, is defined by a pair $\langle \mathcal F, \mathcal A \rangle_P$ where $\mathcal F$ is a family of data structures, each one solving $P$ with a proper trade-off in the use of some resources (e.g. time, space, energy), and $\mathcal A$ is an optimisation algorithm that selects in $\mathcal F$ the data structure that best fits an instance of $P$.



For more details on the project, have a look at its full description here.
Paolo Ferragina and Giovanni Manzini, together with Michael Burrows (Google) have received the 2022 ACM Paris Kanellakis Theory and Practice Award for inventing the BW-transform and the FM-index that opened and influenced the field of Compressed Data Structures with fundamental impact on Data Compression and Computational Biology.
Giorgio Vinciguerra won the 2022 PhD thesis award from the EATCS Italian Chapter for his research on “Learning-based compressed data structures”.
The paper by Domenico Amato, Giosuè Lo Bosco, Raffaele Giancarlo titled “On the Suitability of Neural Networks as Building Blocks for the Design of Efficient Learned Indexes” got the best paper award at EANN 2022.
A benchmarking platform to evaluate how Feed Forward Neural Networks can be effectively used as index data structures.
A collection of methods for performing element search in ordered tables, starting from textbook implementations to more complex algorithms.
A grammar compressor for huge files with many repetitions.

A compressed rank/select dictionary exploiting approximate linearity and repetitiveness.

A data-aware trie for indexing and compressing a set of strings.
A Combination of Convolutional and Recurrent Deep Neural Networks for Nucleosome Positioning Identification.
This package proposes compression strategies for fully-connected and convolutional layers of deep neural networks, including pruning, quantization and low-rank factorization.
A software library for the distributed analysis of large-scale molecular interaction networks.
Software to analyze gene expression data of a set of samples belonging to two different populations, typically the one referred to healthy individuals and the other to unhealthy ones.
An extensible framework to efficiently compute alignment-free functions on a set of large genomic sequences.
A general software framework for the efficient acquisition of FASTA/Q genomic files in a MapReduce environment.
A SPARK software system for the collection of $k$-mer statistics.

A compressed bitvector/container supporting efficient random access and rank queries.
A software library to speed-up sorted table search procedures via learning from data.

A monotone minimal perfect hash function that learns and leverages the data smoothness.
Compressed rank/select dictionary based on Lempel-Ziv and LA-vector compression.
Massive matrix multiplication on RePair-compressed matrices.
Data structures supporting Longest Common Extensions and Suffix Array queries, built on the prefix-free parsing of the text.
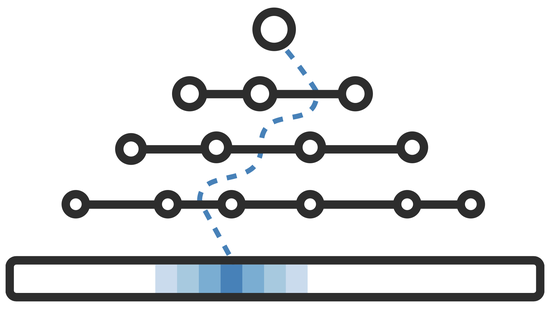
A data structure enabling fast searches in arrays of billions of items using orders of magnitude less space than traditional indexes.
Python library of sorted containers with state-of-the-art query performance and compressed memory usage.
Compression strategies and space-conscious representations for deep neural networks.
The numerous paper presentations given at conferences by the project members are not included in the above list.
List of students, postdocs, and collaborators involved in the project:
List of PhD thesis related to the project:
*Joint Ph.D. course in “Genomics and Bioinformatics” between Università degli Studi di Milano and the Joint Research Center (JRC) di Ispra. The first year of the course has been funded by the project.